



Plus: a neat prompt hack that improves language model performance dramatically.
Welcome to The Cusp: cutting-edge AI news (and its implications) explained in simple English.
In this week's issue:
- AI-generated stock photography ripe to dethrone Shutterstock & alternatives
- Effortless question-answering on PDFs & images could save millions
- A clever prompt hack to improve language model performance
Let's dive in.
Extract, classify, and answer questions directly from PDFs—in seconds
Millions of interns, salaried employees, and executives are employed at major corporations around the globe, and their #1 job duty is extracting or summarizing information from PDFs.
This industry, more accurately referred to as data analytics and extraction, is a hundred-billion dollar market.
It's also extremely automatable, and the companies of tomorrow are already implementing advanced extraction tools to do orders of magnitude more than the competition.
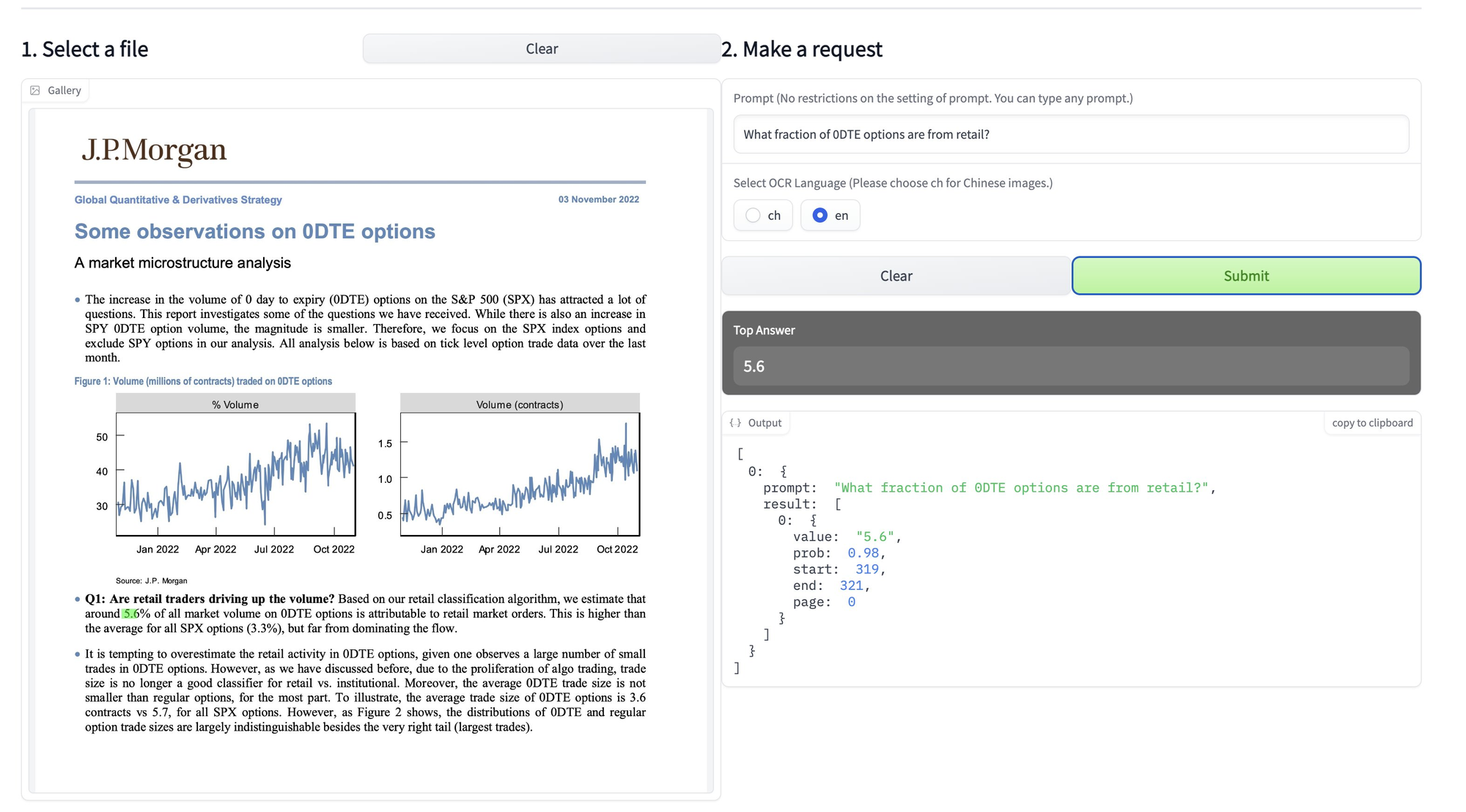
DocQuery is just one example. It's an AI tool that can read PDFs & automatically extract data—including key text, questions, and even figures from surveys—in seconds.
It operates off of a natural language interface, is intuitive to use, and it's free: the model is hosted on HuggingFace, and you can download & extend it however you wish.
How can we take advantage of this?
Models like this are being slept on because there's a general lack of understanding of how they can be integrated into business workflows.
But the applications are endless.
For example, a large enterprise could use DocQuery to:
- Automatically generate summaries of key points from financial PDFs: metrics, key points, figures, etc.
- Classify documents by type (e.g. invoices, contracts, legal paperwork) for easy forwarding to the correct department.
- Reformat PDFs flexibly by extracting key text & figures, then rearranging them into a new template.
- Pull data from customer surveys to generate actionable insights.
Any of these tasks might take an hour or more for an experienced professional to complete. But by adding flexible data extraction to your pipeline, you can get the same results in seconds.
For instance, I implemented a (very) simple system with contracts at 1SecondCopy that saves me 60-90 minutes/week.
We sometimes receive three or four contracts a day. They're usually NDAs, work agreements, and so on. Naturally, it takes a fair amount of time to parse the legalese.
But with DocQuery, I simply ask a question, like "how much money is the payment for?" or "what are the payment terms?" and get an answer in seconds.
Keep in mind that we're an extremely small startup—this approach could save millions at your average small to mid-sized business.
AI-generated stock photography soon to dethrone Shutterstock & alternatives
Pixel Vibe is a new, AI-generated stock photography platform. And its user experience destroys Shutterstock, Getty, & other traditional stock media.
Instead of having to curate specific search terms, or spend hours hopping from platform to platform, you just click on an image & it pulls up hundreds of similar ones for you to choose from.
Eventually, you converge on the photo you had in mind—without ever needing to type a search phrase.
This is just another step on the spectrum of AI image tool possibilities. And with stable diffusion now at the point where the quality is, in many respects, indistinguishable from real DSLR photography, the stock media industry will soon be reeling.
How can we take advantage of this?
Pixel Vibe launched on Product Hunt less than 36 hours ago. And, don't get me wrong, the UX is certainly significantly better than traditional stock websites—but that's not saying much.
This space is extremely ripe for the right company to sprout and disrupt the competition. Stock media companies are already bleeding with DALL-E 2 and Stable Diffusion (it's only a matter of time before they start hemorrhaging).
A next-generation platform capable of generating—and then intelligently searching for—images like the one below could easily siphon that loss into a winning business model.

So, what if you wanted to do this in practice?
- Use or train a model similar to Lexica's Aperture. I'll spare you the details, but if you choose to train yourself, you'd fork Stable Diffusion and fine-tune on DSLR photos.
- Scrape Shutterstock or Getty to create a keyword list. 100K keywords or more is optimal.
- Now that you have a keyword list, generate a style phrase list: lens types, apertures, and other photography terms. Think phrases like Sigma 30mm f1.4, macro, bokeh, etc.
- Generate a million or more images by iterating over each keyword with a different style phrase. If one keyword is smiling woman on street, for instance, a single generation might be smiling woman on street, sigma 30mm f1.4. Another might be smiling woman street, canon 50mm f1.8 (if you're curious, this is exactly how I created 1SecondPainting).
- Store the images, their text embeddings, & their image embeddings somewhere like AWS. Alternatively, you could skip the text/image embedding step and run your images through another model that generates captions or tags for each image (for faster searches).
- You now have a similar backend with many more images. All you'd need to do is improve the customer UX on the frontend—by producing faster results, creating a better design, etc.
- Lastly, go the Netflix route and charge an affordable monthly subscription. Per-image models just won't work in a future where regular people have state-of-the-art image generators at their fingertips.
Someone is probably doing this as we speak. And the person that capitalizes on this first will see tremendous upside.
Improve language model performance with this prompt engineering hack
Few-shot prompting is a strategy where you provide several examples of what you want your language model to do, and then it uses the context to steer toward the correct result.
A silly use case for goofy title generation:

Performance almost always grows monotonically with the number of examples provided. Which makes sense—if you give the model more context, why wouldn't it give you a better answer?
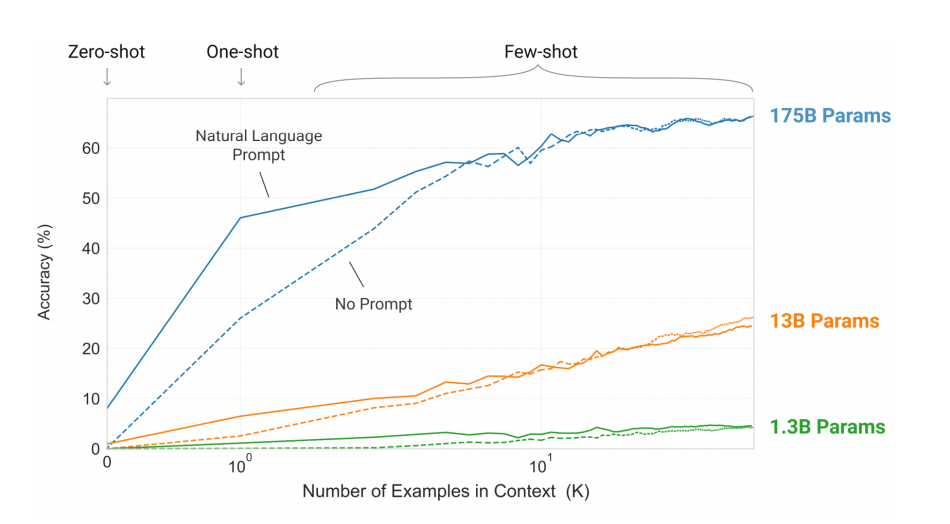
But it's difficult to know exactly what kind of examples to provide. Especially if your prompt is dynamic and always changing, like if you were integrating it with an application.
An additional factor is the token length of your prompt—the more tokens you send in a single query, the lower the performance of the model usually becomes because of the mathematics of self-attention.
So it's in your best interest to include a set of examples that is both short and relevant. If you do, model performance increases because of the improved context and short length. That's where this hack comes in.
How can we take advantage of it?
The trick, posted by @mathemagic1an on Twitter, is to compare the text embeddings of your examples to your prompt, and then pick the most relevant set (by cosine similarity).
Clever prompt eng trick for those who haven't seen it:
— Jay Hack (@mathemagic1an) November 23, 2022
If you have many examples that can serve as "few-shot" guidance ({example[0]['input']} etc. below)
=> select these samples dynamically at runtime based on semantic (embedding) similarity with your {input}
Big perf gains! pic.twitter.com/JMYqMUvoRN
That may sound complex if you're not already familiar with the mathematics behind machine learning. But to break it down:
- Text embeddings are a numeric representation of your text. For instance, the phrase "Google is great" can be represented as a large, multidimensional matrix.
- First, you'd calculate the text embeddings of your prompt (on its own) and your examples (on their own).
- Then, you'd compare the text embeddings using a distance metric, cosine similarity, that calculates the difference between them.
- Lastly, you'd pick the embeddings that are the closest numerically (i.e have the largest cosine similarity) and add them as few-shot examples.
- Now you have a contextually relevant 'primer' for your language model, which leads to better performance when you prompt.
Creative hacks like this are being discovered & implemented all the time. It's one of the reasons I love machine learning so much.
That's a wrap!
Enjoyed this? Consider sharing with someone you know. And if you're reading this because someone you know sent you this, get the next newsletter by signing up here.
See you next week.
– Nick


