



Plus: how to beat GPT-3 performance at 1% of the cost.
Welcome to The Cusp: cutting-edge AI news (and its implications) explained in simple English.
In this week's issue:
- New: AI-generated piano covers indistinguishable from human-created ones
- Instantly upsample any video from the '60s, '70s, or '80s by more than 10x.
- How fine-tuning crushes parameter size in language model performance
Let's dive in.
Make realistic piano covers with AI in seconds
Pop2Piano is an impressive new model that generates realistic piano covers of popular songs that are indistinguishable from human-played recordings.
The model was trained on a dataset of ~300 hours of source files & piano covers. By putting source audio side-by-side with the piano version, the model learned to map the melodies and rhythms of pop songs onto a MIDI piano score.
I should note: the output of the model is a MIDI track (an assortment of notes). So technically, you could map these outputs onto any sound—piano, guitar, etc.
How can we take advantage of it?
Piano covers are huge on social media. Songs like this commonly get tens of millions of views.
Until now, you needed to be extremely skilled—as in 5+ years of experience—just to create sheet music, let alone a high-quality, enjoyable piano cover.
But with Pop2Piano, you only need the source audio file, a Colab, and a few minutes.
Plus: given how the lab is significantly less well-known than most AI research groups, this probably won't make headlines for at least a few months.
Between now and then, you could:
- Get a list of the top 5,000 pop songs,
- Generate a piano cover for each,
- Export the MIDI into a high end piano VST like KeyScape and give your track realistic timbre, reverb, etc (you could probably win music awards!)
- Create procedural videos using something like SeeMusic
- Release dozens of videos per day on YouTube/TikTok, release covers on Spotify, and take advantage of organic traffic for that keyword
- Bonus: create sheet music using a service like MIDI Sheet Music and sell it on websites like ArrangeMe
In a few years, the opportunities to rank in a world dominated by synthetic content will be few and far-between. But first movers can take advantage before platforms change their algorithm to accommodate for that.
Fine-tuning can crush parameter size in LLMs
Bigger is always better, right?
Wrong.
When GPT-3 came out, people marvelled at its size. 175B parameters for a language model was unheard of at the time.
Mathematicians and engineers began extrapolating performance based on parameter count. Thoughts were generally: "If 175B is this useful, how useful would a 400B model be?"
But while size is important for performance, it turns out it's nowhere near as important as how you fine-tune. And the results speak for themselves.
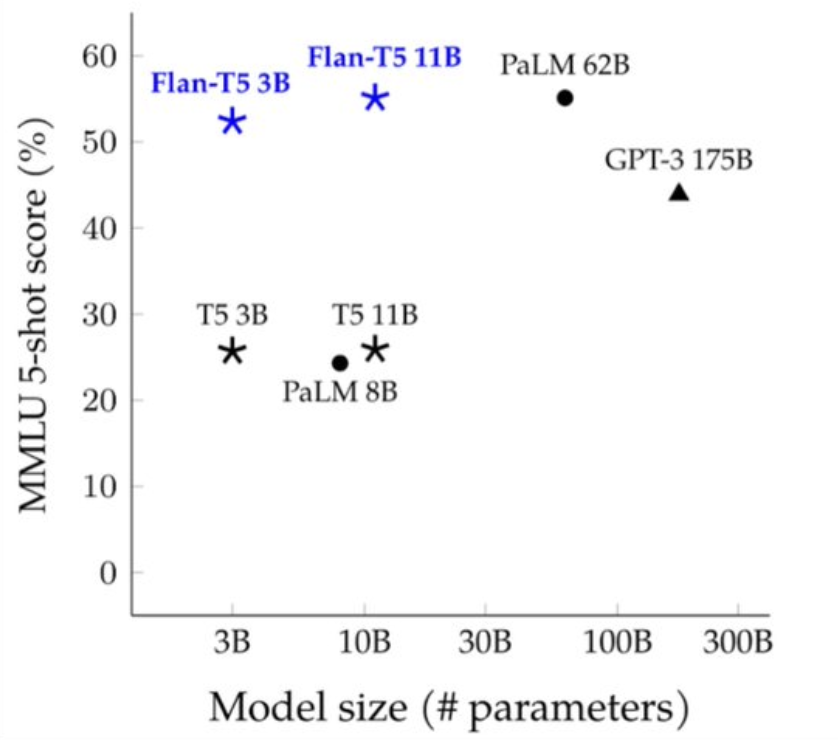
For those not in the know: the MMLU (Massive Multitask Language Understanding) is a benchmark that gauges model performance. It's similar to a highschool exam, in that its filled with questions that test both reading comprehension and logic.
When compared to GPT-3 175B, Google's Flan-T5 11B does 10% better at less than 1/16th the size.
The difference between the two? GPT-3 175B wasn't fine-tuned.
Both models were trained on a massive corpus of general text data. But Flan-T5 11B went just a bit further, and used the last few percentage points of their training cycle on highly-relevant, purposefully-formatted examples that matched MMLU's question set.
How can we take advantage of it?
It's obvious that fine-tuning improves performance. That's not the revelation here.
The important takeaway is this: fine-tuning makes performance extremely accessible.
Most individuals and companies would never be able to train an LLM from start to finish because of the prohibitive compute costs (often $2M+).
But fine-tuning a model that already exists? Easy. Your cost might be just 1% of the gross model expense.
And given that you get such disproportionate results with that spend, it's a no-brainer for any large company looking to marry the flexibility of AI with the procedural rigor of their own systems.

For instance, your company could do the following with just a few ML engineers and a modest compute budget:
- Download BLOOM, the open-source 176B equivalent to GPT-3,
- Prepare a dataset of 1M+ records (where each record includes a prompt with the problem you're trying to solve, and a completion with its correct answer formatted to internal specs),
- Train a vastly more capable model for <1% of the total compute cost of BLOOM (which was estimated at ~$7M)
With a 176B parameter size model that's sufficiently fine-tuned, you can achieve more or less anything you set your mind to. For instance, you could:
- Flexibly classify tens of thousands of incoming queries per hour to the correct department without human intervention.
- Intelligently enrich contact data when a new entry is made to your CRM.
- Describe commit history in simple English to non-technical project managers.
You could instantly double the value of ingoing/outgoing communications, create relevant company documentation in seconds... the list goes on. Imagine the value to an enterprise institution like Microsoft, or a CRM company like HubSpot.
As someone that uses AI in their daily work, this is what I'm most excited about.
Instantly upsample pre-90's video by more than 10x
When S-Lab, an AI lab out of Nanyang Technological University, applied their CodeFormer model to video clips from the 1960s, the results were shocking.
There's no way to quantify the exact upsampling ratio, as CodeFormer works primarily on faces. Pixels around the neckline, for instance, are much less likely to change.
But if I had to estimate, CodeFormer probably increases perceived resolution by at least ~4x across the video, with facial areas (most noticeably the eyes and mouth) closer to 10x.
How can we take advantage of it?
CodeFormer was released earlier this year. But it and its future siblings are going to have a massive impact on older digital media.

Pre-2000, simple, lossy compression techniques were broadly employed to compensate for slow video transfer speeds between networks.
If you wanted to watch a live clip of a dance performance, for instance, you were guaranteed to receive a clip at least 3x-4x lower quality than what the camera shot. And that's not accounting for the differences in camera tech.
Because of this, there are hundreds of thousands of low-quality videos on the internet ripe for the picking. To take advantage of them, you could:
- Upsample tens of thousands of clips—commercials, news segments, comedy shows, etc, and release them on social media (YouTube, TikTok)
- Create a CodeFormer-like service that specifically targeted old home videos. Angle: "see your mother's smile the way it was meant to be seen."
The search space for it exists. And "home video" is a relatively antiquated term that ensures you'd target people in their 40s and 50s (who find this stuff more impressive than the younger generation anyways).
That's a wrap!
Enjoyed this? Consider sharing with someone you know. And if you're reading this because someone you know sent you this, get the next newsletter by signing up here.
See you next week.
– Nick