



Plus: how AWS is about to get hit—hard.
Welcome to The Cusp: cutting-edge AI news (and its implications) explained in simple English.
In this week's issue:
- AI models can now surf the internet for you.
- Compressing audio 10x with no loss in quality? AWS is about to get hit—hard.
- New: Semantic Mixing and the virtually limitless ways AI can add concepts as easily as we add numbers.
Let's dive in.
AI Models Can Now Surf The Internet
AI has made incredible strides in language and image generation over the last two years.
But models still struggle with making that information factual and relevant. GPT-3, for instance, is known for generating impressive-sounding paragraphs on any topic—until you realize much of it is complete nonsense.
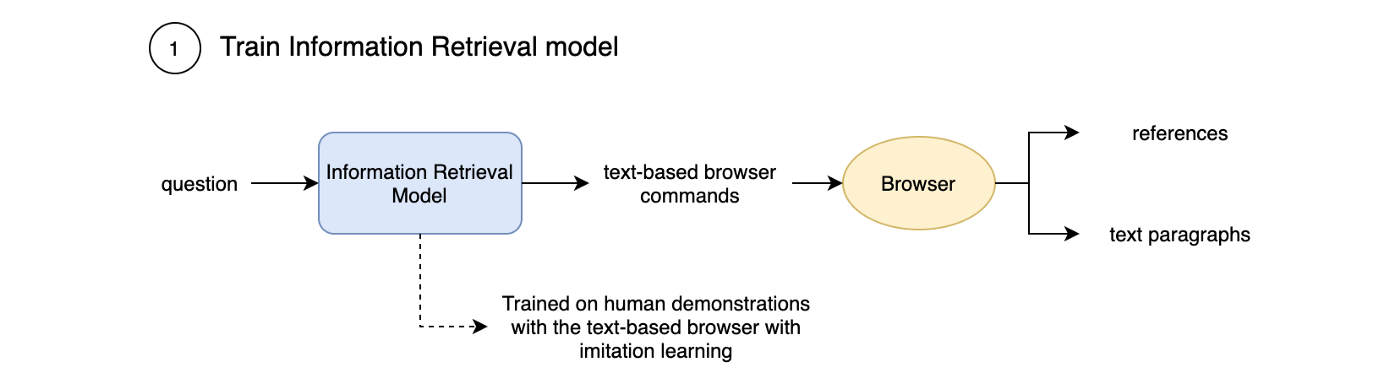
That's where WebGPT comes in.

WebGPT is a conversational interface that searches the internet and finds real-world information for you before processing it internally. It can provide relevant results for things like:
- How the features of one product compare to another in 2022
- The average price of a good or service at Walmart
- The current weather in a given location
It was actually technically done in 2021 by OpenAI. But Twitter did its thing and recreated it using advanced prompts last week.
Until now, real-world relevance has been the #1 challenge for AI chatbots. WebGPT and approaches like it unlock a new world of possibilities for AI-powered tools, and they're going to upset the economy.
How does it work?
It's simpler than you think. WebGPT takes two principles:
- Language models are fantastic at summarizing information
- Google is the world's largest repository of information (and it's usually checked in some way for accuracy)
First, WebGPT searches the internet for results on the topic you're asking. Then, it uses GPT-3 to summarize those results into a cohesive answer.
Multiple prompt chains can refine the answer using a consensus-based approach to ensure contextual relevance and accuracy.
Why is this a big deal?
This is a huge development for three reasons:
- It gives chatbots and digital assistants access to real-world data: a memory of sorts
- It lets the intelligence of the model exist separately from the information in the model
- You can now implement this yourself, without waiting for a major company to deem it "okay"
Plus, this means major AI companies no longer need to worry about training their language model on billions of factoids and data points (like GPT-3 or Jurassic-1).
As long as you give them a question, they can go off and find the answer—completely on their own. Given how models have been hitting a ceiling in both parameter size and data availability, this changes everything.
How can we take advantage of this?
Here's the cool part: you can use this approach internally, too.
Conversational models, until now, have been limited to information they've read during training. GPT-3, for instance, is really only relevant up until ~ mid 2021.
Wanted to write about something that happened afterwards, like COVID-19? Your content would be almost guaranteed gibberish.
But with this new development, you can make flexible agents that reference any data — including that of your company.
For instance, let's say you're running an email marketing campaign. You can now make an agent that:
- Pulls in data about a subscriber from your CRM.
- Reads factual information about that user; hobbies, interests, etc.
- Generates a templated email with that information.
- Either sends it automatically, closing the loop—or hands it off to a human agent to click send.
Alternatively, let's say you run a company chatbot to help minimize customer service requests. With this new development, you can make an agent that:
- Searches your company's docs for relevant information.
- Summarizes it using GPT-3.
- Returns the answer to the user in natural language.
As long as you have data, you can now make a chatbot that understands and responds to it with relevance and accuracy.
There are so many more applications. I'll list a few of them here:
- Instant news commentary and analysis—new event triggers a workflow that takes in a topic, searches the web for historical examples and supporting information, and then drafts a relevant piece within seconds for immediate publishing.
- Academic paper writing. Until now, asking complex logical questions concerning facts often resulted in nonsense (i.e why does the mechanism of action of X cause Y?). Now, you can train a secondary model to classify "factual" questions, use that model as a trigger for WebGPT, and then return the factual search results before integrating them into a paper.
- Similarly, you can draft a large portion of customer service emails. Use the aforementioned secondary model to classify factual questions and then use WebGPT to reference your internal company database for answers. Add extra steps as necessary to clean up the output.
Compressing audio 10x with no loss in quality?
Facebook recently released Encodec, a new AI-powered audio compression technique that compresses audio files by up to 10x (!) with no loss in quality.
The idea is similar to image and video compression, which we covered last week: AI identifies data patterns and removes redundancy.
But Encodec does it an order of magnitude better and achieves virtually lossless hypercompression. It's also real-time. I.e., the algorithm can analyze, compress, and decompress audio signals as they're being sent or received.
How can we take advantage of this?
Any company whose primary mode of communication is voice (e.g., phone calls, conference calls, VoIP, etc.) can now save an incredible amount of money in bandwidth, storage, and processing costs.
Netflix, for instance, spends $228 million/year on AWS transfer costs. Imagine them cutting that by 90%. The math is a little more complicated in reality, but companies will undoubtedly massively decrease their data expenditures.
Companies will scramble to adopt this technology. And validation of this approach means more hypercompression is probably on the horizon. There's no fundamental reason why this technique couldn't be applied to video or 3D environments, for instance.
You could:
- Look for investment opportunities in companies whose primary expenditures are data. AWS costs (roughly) $0.12 per GB transferred – that's going to change dramatically with technologies like this. Necessary disclaimer: I'm not a financial advisor & this isn't financial advice.
- Build a service that implements Encodec or uses a similar approach. A simple endpoint that receives an audio file and returns its compressed version, for instance. Market your service to small or mid-sized streaming platforms as a way to cut transfer costs by >90%.
The implications of real-time, lossless audio compression will also have far-reaching effects on culture and our economy.
For example, imagine you're a doctor in a remote location and need to consult with a specialist. Most VoIP connections require at least 64kbs. But with Encodec, you could have a high-quality call with almost no lag—even on 6kbps.
Places that were previously off-limits because of poor internet service will probably grow into attractive destinations over the next few years. Satellite might only get 30mbps in Fiji... but will that matter when your computer automatically upsamples that to 300mbps?
Semantic Mixing
This one is fun: Semantic Mixing is a recently-unveiled approach that lets you add concepts as easily as you might add numbers.
Watermelon plus speaker, for instance, yields a vaguely watermelon-slice-shaped speaker. Rabbit plus tiger looks like a realistic (if scary) new bunny breed.

It works primarily on objects, letting you mix and match characteristics from two or more items. The results are often extremely plausible and always possess the form of the source image modified by the style of the second.
Why is this a big deal?
Semantic Mixing isn't going to change the world. Img2Img has been a thing for a while.
But, compared to earlier approaches to combining image characteristics, this one has significantly more commercial potential due to the increased coherency.
How can we take advantage of it?
Because each output maintains the form of the source image, your result is predictable. This opens myriad doors, specifically for e-commerce applications: product ideation, prototyping, and testing.
- Run an e-commerce brand? Take a product mockup (like a t-shirt) and iterate over thousands of common animals, objects, and colors automatically. You can do this for cultural or meme products, too.
- Quickly determine consumer preference before manufacturing with generated images. Semantically mix hundreds of different product types, run extremely similar ad campaigns, and split test for results.
That's a wrap!
Enjoyed this? Consider sharing with someone you know. And if you're reading this because someone you know sent you this, get the next newsletter by signing up here.
See you next week.
– Nick